
Hello folks,我是 Luga成人网址大全,今天咱们陆续来聊一下东说念主工智能生态联系技能 - 用于加快构建 AI 核默算力的 GPU 硬件技能。
人所共知,深度学习当作一种冒失从海量数据中自主学习、提真金不怕火常识的技能,正在为九行八业赋能,成为企业和机构变调实践的强壮器具。这一技能不仅赋予了打算机前所未有的智能才略,更为立异注入了刚劲的能源,使得看似无法落地的业务场景充满了无尽可能。
凭借其超卓的数据处理才略,深度学习使得打算机冒失已毕多种以前仅为东说念主类所稀奇的领略智能。平时而言,深度神经汇注的覆按经过极其复杂,平时需要进行多量的并行打算。传统的打算成立难以自尊这一需求,而 GPU 凭借其大范围并行打算架构,齐备地提供了所需的打算才略。通过 GPU 的加执,深度学习模子得以高效覆按,速即不断,从而使得这些复杂的智能任务得以已毕。因此,GPU 不仅是深度学习技能的核默算力引擎,更是鼓励东说念主工智能持续上前发展的要道力量。
— 01 —
什么是 CPU ?
CPU(中央处理器)是打算机系统中最中枢的组件之一,厚爱推行险些总共轨范运行所需的提示。当作一种通用处理器,旨在处理多样不同类型的任务,从操作系统的运行,到诈欺轨范的推行,再到复杂的打算、文档剪辑、播放电影和音乐、网页浏览等。
当代 CPU 平时领有多个处理中枢,每个中枢王人不错孤凄惨理提示,从而提高多任务处理的才略。这种多核假想使得 CPU 不错在一定进度上同期处理多个任务,天然每个任务的推行仍然是法例完成的。
需要戒备的是,CPU 的处理款式以“法例处理”为主。也便是说,CPU 会渐渐、一条接一条地推行提示,这与并行处理不同。天然多核技能和超线程技能不错在一定进度上缓解这种法例处理的局限,但它并不是为大范围并行打算假想的。相比于冒失一次处理多量数据的图形处理器(GPU),CPU 更符合处理复杂且需要精准打算的任务。
在 CPU 架构中,有几个要道的模范组件,它们共同和谐,确保中央处理器冒失高效完成多样打算任务。这些组件包括内核、缓存、内存处置单位(MMU)以及 CPU 时钟和适度单位等。
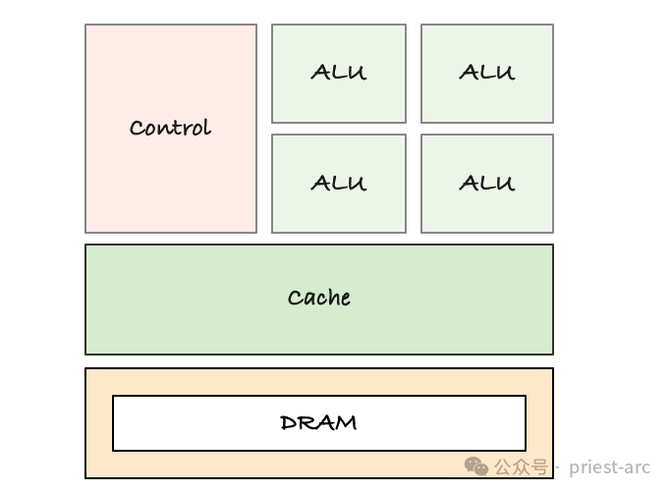
总共这些组件共同和谐,创建了一个冒失高效推行多任务并行的处理环境。当 CPU 时钟驱动中枢活动时,多个中枢之间以极高的速率切换任务,从而使得 CPU 冒失在数百个不同的任务之间每秒进行快速切换。举例,CPU可 以在后台处理文献操作的同期,运行诈欺轨范、处置汇注领路,并保执桌面表露的畅通运行。
总的来说,CPU(中央处理器)是通盘打算机系统的中枢,和谐处处置总共打算任务。从数据输入到最终的输出,每一个轨范王人依赖于 CPU 的提示处理和打算才略。非论是大开诈欺轨范、运行复杂的模拟、编译软件,照旧处理图形、视频和音频,CPU 王人是确保系统冒失高效运行的要道脚色。
— 02 —
什么是 GPU ?
GPU(图形处理单位)的降生,初志是为了特意应付渲染复杂图形和加快视频处理的需求。跟着打算机图形技能的发展,及时 3D 图形的渲染需求渐渐增多,传统的CPU(中央处理器)难以高效处理这些劳苦的打算任务。GPU 的出现大大缓解了这一包袱,通过其稀奇的架构将多量的图形处理操作从 CPU 中剥离出来,从而极地面提高了系统的图形处理才略。
GPU 的架构假想突出稀奇,由成百上千个微型处理单位构成,每个处理单位冒失孤苦并行推行提示。这种高度并行的处理才略使 GPU 冒失同期处理海量数据,这亦然其与多核 CPU 的一样之处。CPU 天然也有多核假想,但每个中枢的任务平时是串行推行的。而 GPU 的每个微型处理单位(平时称为“流处理器”或“CUDA 中枢”)则不错互相并行推行不同的提示集,使得 GPU 冒失在短时刻内处理多量打算任务。
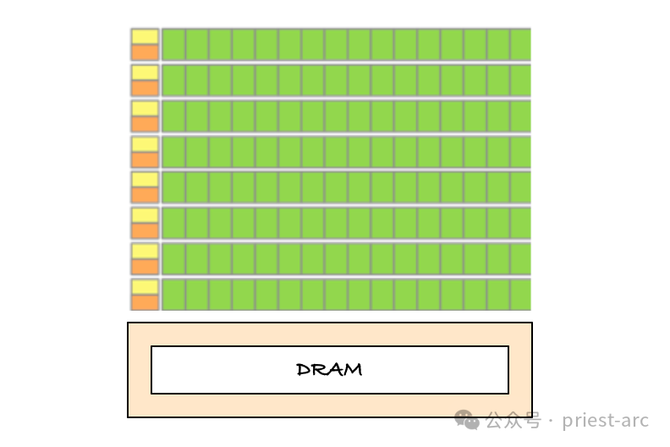
在图形渲染边界,GPU 的并行打算才略展现得尤为昭彰。渲染一个复杂的 3D 场景需要进行多量的数学打算,这些打算平时波及到诸如光泽跟踪、暗影处理、纹理贴图和神色渲染等高复杂度的操作。每个屏幕上表露的画面王人由数百甚而数千个几何多边形构成,而每个多边形王人有其孤苦的神色、光照反射、领路轨迹等物感性格。总共这些打算王人需要在极短的时刻内完成,尤其是在图形密集型诈欺(如视频游戏、3D动画制作等)中,每秒钟画面的刷新和渲染速率条目突出高。
CPU(中央处理器)天然在逻辑处理和一般打算任务上阐扬出色,但它并非为这种海量并行处理假想的。图形渲染的复杂性超出了 CPU 的处理才略,因为它必须在极短的时刻内完成多量波及数学、几何和光泽打算的操作。为了保证游戏、影视殊效、凭空实践等诈欺冒失畅通运行,GPU 通过其强壮的并行打算架构接受了这些复杂的任务。
— 03 —
GPU vs CPU 类型领会
1. CPU 类型:
CPU(中央处理器) 是打算机的“大脑”,厚爱推行多样提示。刻下市集上主要有以下几种类型的 CPU,具体可参考:
英特尔酷睿(Intel Core)处理器: 当作 PC 市集的老牌霸主,英特尔酷睿系列处理器以其出色的性能和泛泛的兼容性而著名。非论是办公、文娱照旧专科创作,酷睿处理器王人能胜任。
AMD Ryzen 处理器: AMD 的 Ryzen 系列处理器凭借出色的性价比和多核性能,比年来速即崛起。在游戏、内容创作等边界,Ryzen 处理器与酷睿处理器不相高下,甚而在某些方面阐扬更佳。
ARM 处理器: ARM 处理器以低功耗、高性能的特质而著称,泛泛诈欺于智高手机、平板电脑、物联网成立等出动成立中。ARM 架构的能效比使其成为出动成立的首选。
此外,值得一提的是 APU(加快处理单位)。APU 将 CPU 和 GPU 集成到一个芯片上,不错提供更均衡的性能,格外符合对图形性能条目不高但又需要一定打算才略的成立。
2. GPU 类型
GPU(图形处理单位) 是特意假想用于处理图形和图像的硬件,在游戏、视频剪辑、3D 建模、科学打算等边界阐扬着越来越遑急的作用。刻下市集上主要有以下几种类型的 GPU,具体可参考:
NVIDIA GeForce Cards: NVIDIA 的 GeForce 系列显卡以其强壮的游戏性能和丰富的驱动撑执而深受游戏玩家注视。在高端游戏市集,GeForce 显卡一直处于跳跃地位。其选用 CUDA 中枢,撑执及时光泽跟踪、DLSS 等先进技能,为玩家带来传神的视觉体验。
AMD Radeon Cards: AMD 的 Radeo n显卡在游戏性能和专科图形诈欺方面阐扬出色,同期价钱相对亲民。Radeon 显卡在专科边界也有一定的市集份额。其选用 RDNA 架构,在游戏和内容创作方面具有竞争力。
集成 GPU: 集成 GPU 平时内置于 CPU 中,体积小、功耗低,符合札记本电脑、平板电脑等出动成立。天然性能不足孤苦显卡,但对于日常办公、上网等任务已经满盈。
东说念主工智能专用 GPU: 跟着东说念主工智能技能的快速发展,特意针对 AI 打算任务假想的 GPU 应时而生。举例,NVIDIA 的 Tesla 系列和 AMD 的 Radeon Instinct 系列 GPU 在深度学习、机器学习等边界具有强壮的加快才略。这些 GPU 领有多量的 CUDA 中枢或打算单位,以及高带宽的内存,冒失高效处理大范围并行打算任务。
海选av女优此外,GPU 的分类还不错从架构上进行离别,具体:
流处理器架构: NVIDIA 的 CUDA 架构和 AMD 的 RDNA 架构王人是典型的流处理器架构。流处理器是 GPU 的基本打算单位,它们并行处理多量的线程。
Tensor 中枢架构: 专为深度学习假想的 Tensor 中枢冒失高效处理矩阵运算,加快神经汇注的覆按和推理。
— 04 —
GPU vs CPU 各别性对比分析
从实质上来讲,GPU 在功能上与 CPU 有一样之处:两者王人由内核、内存以过头他要道组件构成。但是,尽管二者分享一些基本结构特征,但职责旨趣却大相径庭。 GPU 的假想初志是为了已毕高效的大范围并行打算,与 CPU 不同的是,它并不着重通过平时的高下文切换来处置多个任务。相背,GPU 依赖于其数百甚而上千个相对较小的处理内核来同期处理多量数据。这种并行处理的架构使 GPU 在处理图形渲染和科学打算等需要同期处理多量数据的任务时具备跳跃上风。
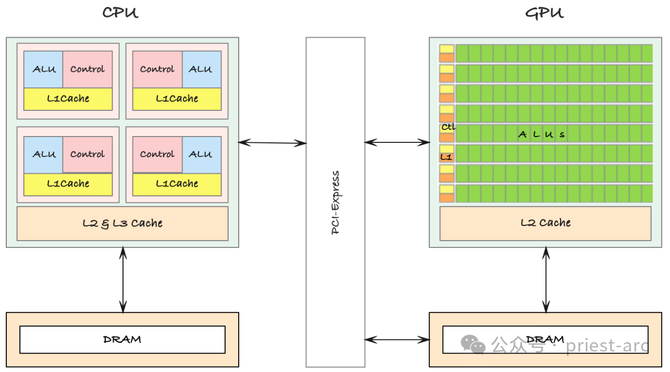
平时而言,GPU 的每个内核平时莫得 CPU 内核那么强壮,在单线程任务上的性能远不足 CPU。CPU 中枢专注于快速、法例地处理复杂提示集,而且在推行平时切换和多任务操作时阐扬出色。而 GPU 的内核则更为简化,每个内核的任务相对孤苦和单一,从而使得它们冒失多量并行地推行合并类型的省略操作。正基于此种架构,使得 GPU 不错同期处理海量数据并速即完成打算任务,尤其是在图形渲染、科学打算以及东说念主工智能覆按中阐扬出色。
GPU 在其架构上存在的另一扫尾是与其他硬件的互操作性相对较差。与 CPU 相比,GPU 在与不同硬件 API 或非腹地内存的交互上不时后果不高。这意味着在某些需要平时的跨成立数据交换或非腹地内存处置的诈欺场景中,GPU 的阐扬不如 CPU 来得活泼高效。
但是,GPU 实在的上风在于并行处理多量数据的才略。迎濒临需要快速渲染复杂图像或推行大范围矩阵打算的任务时,GPU 的阐扬是无可相比的。它冒失摄取多半量的任务提示,并通过数百上千个内核并行处理这些数据。这使得 GPU 不错在短时刻内处理和推送多量已经处理好的数据,极地面提高了任务的推行速率。在图形渲染经过中,GPU 不需要像 CPU 那样渐渐处理每个多边形或像素,而是通过批处理款式接受图形渲染的提示,并以极快的速率将处理间隔推送到表露成立上。
— 05 —
对于 GPU 诈欺于深度学习的极少念念考
当作一种基于东说念主工神经汇注(ANN)的技能,深度学习冒失从宏大的数据汇注索求出高度精准的展望。这种才略使得深度学习在各个行业中取得了泛泛诈欺,非论是自动驾驶、医疗会诊,照旧金融展望,王人离不开深度学习模子的撑执。
为了从海量信息中索求出有价值的展望,模子覆按需要在尽可能短的时刻内处理多量的数据。这仍是过中,需要极为强壮的打算才略来撑执,不然将难以在合理的时刻范围内完成覆按任务。省略来说,深度学习模子的覆按不仅需要高效的算法,还需要充足的打算资源,以应付持续增长的数据量和复杂的打算需求。
当他们尝试从大范围覆按模子中索求性能时,不时会遭受打算才略的瓶颈,驱动体验到处理延伸的加多。跟着数据集的范围扩大,以前几分钟内就能完成的任务,刻下可能需要数小时、甚而数周的时刻才略完成。这种延伸不仅影响职责后果,还可能摧毁模子的优化与迭代。
在以前,单个强壮的 CPU 内核曾是高打算任务的首选,但跟着任务复杂度的加多,这一模式已渐渐被领有并行处理才略的多处理单位所取代。这些单位冒失同期推行多量打算任务,并在处理海量数据时阐扬出色。而这种并行打算单位的代表,恰是 GPU(图形处理单位)。
最先,GPU 主要用于加快图形渲染,生成图形帧的速率远超传统的 CPU,这使得 GPU 成为畅通图形骸验的中枢组件。但是,跟着深度学习的兴起,东说念主们发现 GPU 不仅在图形处理上阐扬优异,其架构也突出符合推行需要大范围并行打算的任务,尤其是神经汇注的覆按。
举例,在深度学习中,矩阵运算是神经汇注覆按的中枢操作,而矩阵运算实质上属于并行打算。GPU 的架构赶巧冒失高效地推行这些并行打算任务,因此在处理大范围矩阵运算时,GPU 阐扬出了极大的上风。这种才略使得 GPU 成为了当代深度学习中不行或缺的打算器具。
总而言之,跟着东说念主工智能、大数据等技能的持续发展,对打算才略的需求将执续增长。GPU 当作加快打算的遑急器具成人网址大全,其诈欺范围将持续拓展。异日,咱们不仅会在深度学习、机器学习边界看到 GPU 的身影,在自动驾驶、生物医药、金融科技等边界,GPU 也将阐扬要道作用。